Anjana Data & LLM Hub
At Anjana Data, we have been involved in data governance in various areas for some time, including ML and MLOPS. During this time, our main focus has been on including data governance frameworks or models that cover these scenarios, thereby not only increasing the reliability of these systems, but also optimising their use and proper development.
By combining our experience in this field with our research into current innovations, we have developed an architectural approach that we have named “LLM Hub”. We believe this approach to be highly interesting, as it enables us to exploit the current and future capabilities of what is known as “Generative AI” in an agile, controlled, scalable and evolvable manner over time.
To explain this, we have organised three sections in which we will discuss the following:
- LLM Hub architecture and system integration in LLM Hub
- Proposed roadmap for integrating Anjana Data into LLM Hub
- Data governance application with Anjana Data on the evolutionary maintenance of LLM Hub and MLOPS mechanics
In this first part, we will begin with a simplified summary of the current state of the “Generative AI” framework, then move on to explain in a simple and high-level way what we call the LLM Hub, what it contributes, the parts that compose it, what and how it integrates systems, and how it can evolve over time.
LLM Overview: State
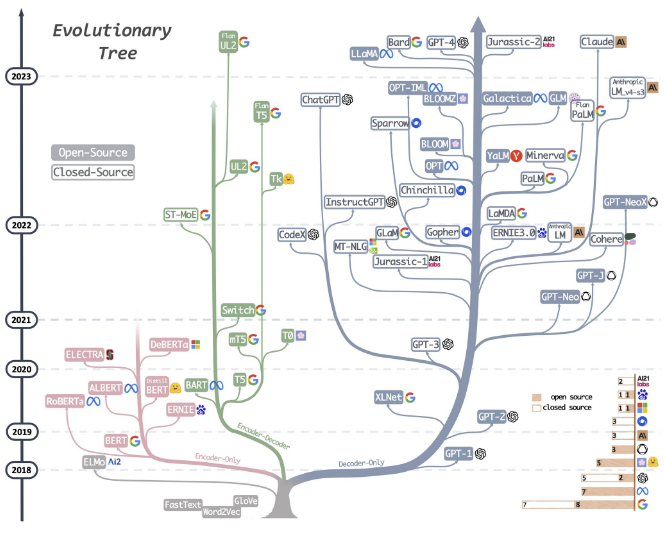
Currently, LLM models under the generative AI framework are booming, and although they are in an early phase in which variants, optimisations, and functionalities are emerging daily, key processes for their generation, distribution, and exploitation have been standardised.
Current capabilities are still far from being able to perform a wide variety of tasks in which a deterministic result is expected. However, on the contrary, there is now a previously unavailable capacity to assist and optimise information consumption, thanks to their great capacity as information aggregators and new response generation capabilities.
In addition, the architecture we propose can recycle and incorporate previously built systems so that they can take advantage of all the current benefits, not only in terms of function and capacity, but also in applying the current standardisation that will optimise their evolutionary maintenance and operation.
LLM Overview: Evolution

Recently, Meta's release of Llama 2 has caused quite a stir, prompting the community and numerous third parties to begin developing variants and optimisations which, together with the existing base, make a large number of models highly interesting.
Thanks to process standardisation, specialised models are constantly emerging as a natural way to optimise the requirements and results of a generic or foundational model for a specific type of task.
At the same time, interest in this area has prompted big players such as cloud providers to promote and build optimised services that are, in many cases, almost ready to use, thereby facilitating adoption. Clear examples include Microsoft's commitment to OpenAI and AWS's AI enhancement with Bedrock. New players are also emerging that directly offer private tenants of their technology, such as ChartGPT Enterprise, or inference as a service, such as the endpoint service (API) offered by ChatGPT or Hugging Face.
In the short term, constant evolution based on improvement, specialisation, and optimisation is expected, but given the high volume of participants, new points of disruption in terms of functionality and capacity cannot be ruled out.
The medium and long term are impossible to predict, but it can be observed that current processes, formats, and mechanisms are practically a de facto standard and are flexible enough to be adjusted to new needs. Therefore, it is reasonable to expect that everything that makes an LLM model exploitable and maintainable will evolve, but there will be no disruptive changes in the short or medium term.
LLM Overview: Current functionality
As already explained, our LLM Hub approach seeks to leverage current capabilities for information aggregation and response generation in user assistance tasks.
The desired outcome is for the user to have an information point that provides them with the information they need in a simple and specific manner. The advantage and innovation is that LLM Hub guarantees that the information provided to the user will be generated from a comprehensive understanding of all the information and contexts, thus avoiding the constant biases of the user themselves, which arise from the fact that it is impossible for a user in one area to have full knowledge of other areas and the impossibility of efficiently consuming static information such as manuals, knowledge bases, etc. This information is usually highly fragmented due to its specialisation and is often not directly accessible.
What makes this desired result possible?
This is made possible by a set of functions that are currently available and applicable on a large scale, but we can focus on the two main ones that interest us:
Content incorporation capability, It is basically the indexing of content so that the model can contextualise questions on the one hand and, additionally, use that information to generate the answer (call-index approach, autogpt, gpt4all).
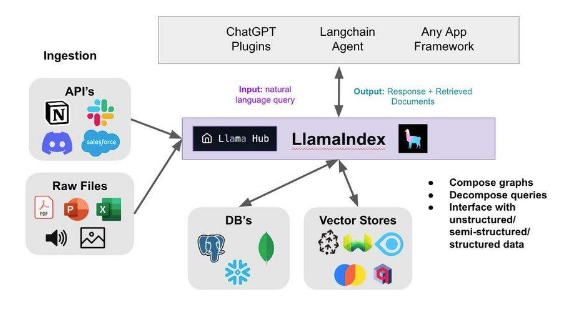
Ability to use agents and tools, This is a generalised approach to the previous point, but one in which a more sophisticated form of “collaboration” is enabled, as agents and tools can interact with indexed content, with each other and with third-party systems, the latter even online, to generate responses. (Langchain approach)
LLM HUB: what and how?
What is LLM Hub?
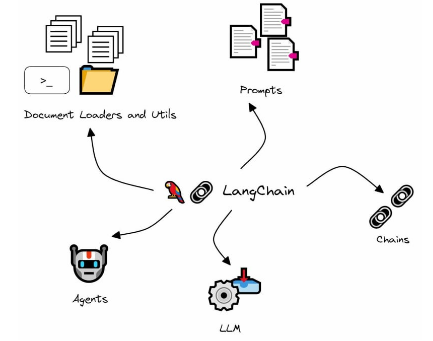
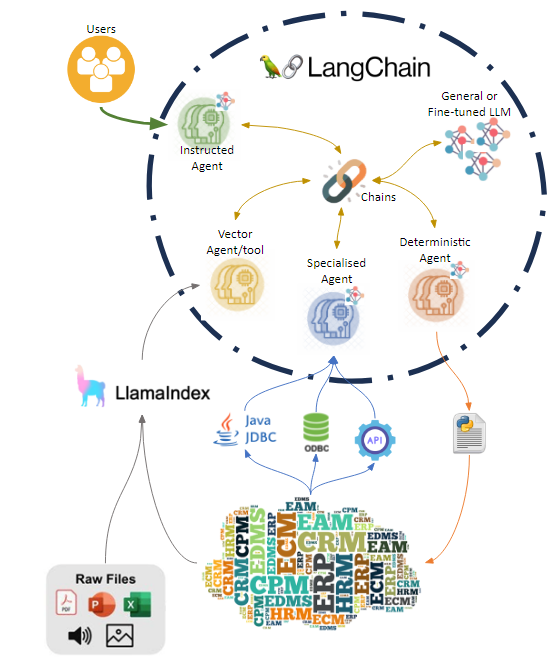
Simplifying it to the bare minimum and taking some liberties, we can define it as a system that contains multiple models, indexed information, agents, and tools in an environment in which each one's functions are used to collaborate in generating a response or activity under certain rules.
How does it do that?
The system relies on LangChain functionality to orchestrate activity and includes rules for segmenting access to information and tools, applicable at various points to achieve the key set of functionalities:
- Incorporating direct online and offline information through tools and indexing, the Llamaindex framework has standardised intake and updating, while llamaHub provides the usual connectors and the possibility of implementing new ones or specialisations of existing ones.
- Incorporation of specialised models, agents and tools, since fine-tuning models is affordable, it is a mistake not to exploit it to adapt general or foundational model behaviours to specific tasks or areas of knowledge.
- Segmentation of access to information based on user profiling; the agents with which the user interacts have rules that restrict the use of certain agents, tools, and sources of information to which the user should not have access.
- Agents for specific uses: agents can be created that specialise in certain tasks or areas, and these agents can even have their own LLM model and tools. However, both the models and the tools can be shared between agents.
LLM HUB: where?
One of the major problems today is assuming the computing cost required for a large-scale application within companies. Although models and techniques are being optimised on a daily basis, the number of possible models to be executed and their scale can entail high costs, and they are not designed to be able to release resources, scale on the fly, or start up within a reasonable time frame.
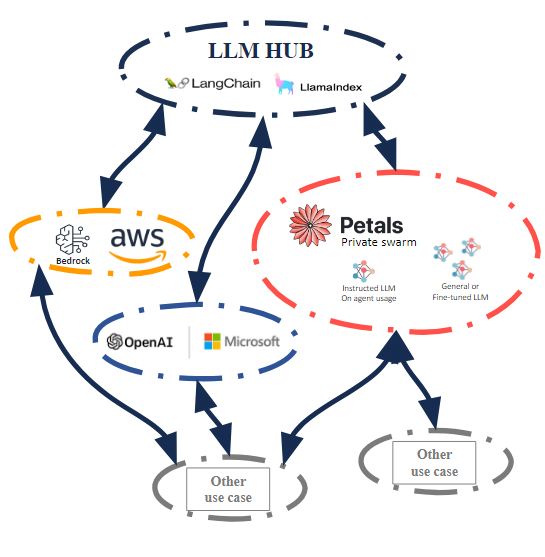
At this point, the use of LLM Hub architecture thanks to LangChain allows us to separate the requirements and infrastructure necessary for the execution of the models from the rest of the components. This not only gives us the ability to scale up later, but by making the models and their computation independent on a separate and agnostic point, we can also share that computing capacity for multiple use cases and third parties other than LLM Hub.
It can take two forms, which may even coexist:
- Private farms, particularly suitable for preserving the location of more sensitive private content, there are classic and container-based alternatives, but in this regard, we would suggest evaluating Petals, as it offers a range of additional features and highly interesting “box” automation.
- Third-party services, There is more variety on offer, but while it is true that some of them create vendor lock-in at certain points, fortunately there are also inference endpoint services that will keep the LLM Hub agnostic at all times. In any case, this LLM Hub architecture can be perfectly implemented on services such as AWS Bedrock, which does create lock-in, but not a loss of functionality.
LLM HUB: Why Petals?
As we have discussed, we believe that evaluating this software (or functionally similar software) is of great interest, and we can quickly review, without going into technical detail, what it offers apart from the obvious gains in privacy and security due to the non-mandatory intervention of third-party infrastructure or management.
The inclusion of private farms based on Petals technology unlocks the ability to scale and dimension in an agile and controlled manner, providing LLM Hub with computing capacity scaling and additionally offering the ability to fragment the required computing across multiple nodes, thereby gaining both load balancing and high availability. Let's look at the three key points that enable this exciting capability:
Required capacity fragmentation
Petals segregates models by layers, which are distributed among the available nodes. This gives us the ability to distribute models among nodes, adding their capacity to meet the necessary capacity requirements.
Horizontal scaling
Along with the fragmentation capability, Petals is forced to generate a logical request routing network that balances between nodes that naturally have the same layer of the model. Therefore, nodes can be scaled by assigning them to the same model so that they replicate layers or even redistribute them (the former is recommended as it does not involve unavailability and gains redundancy).
Vertical scaling
Given the hot horizontal scaling capacity, vertical scaling can also be applied by replacing hot nodes with nodes with greater unit capacity. This can be done using a rolling update to avoid downtime.
LLM HUB: how to integrate systems?
Given that the incorporation of models, sources, agents, and tools into LLM Hub is flexible and incremental, any third party can establish an integration roadmap by contributing any of these components at any time and incorporating some or all of them, as each one provides independent functionality.
In any case, it is advisable for operating systems to try to deliver at least a connector and agent or tool in a package, as these two components are highly synergistic and enable LLM Hub to generate information that is significantly different from other previously available information systems.

Llama Hub connector
Generation of a new connector that extracts the information contained in the product so that it can be easily indexed, allowing queries to be contextualised or the information to be used in a general way by any model, agent or tool. On documentary knowledge base platforms, the available connectors can be used to directly integrate that documentation.
Specialised Agent / tool
Generation of an agent and/or tool that, when registered or used, adds to LLM Hub the ability to consume system information. Thanks to prior contextualisation, agents can make use of query endpoints (search and similar) or even consume data in databases to complete the generation of the response with online information.
Deterministic Agent
Generation of a Langchain agent that, once registered, allows the HUB to perform actions in the third-party system on behalf of the user. The spectrum to be covered is very varied, so it is recommended to group the actions into tools and, in the case of large-scale actions, to generate more than one agent so that each one can work on segmenting actions and tools in the most appropriate way.